Statistically speaking, standard deviation is just a measure of dispersion or spread in a distribution. For example, the mean score in your class’s chemistry final might be an 85 with a range of say 30 to 95. The range is a measure of dispersion.
Standard deviation is just another way to measure spread.
To compute a standard deviation
Compute the difference of each score from the mean
Square the difference
Sum these squared differences
Find the mean of the squared differences by dividing by the number of observations —> this is the variance
Take the square root of variance to find the standard deviation
Standard deviation is useful because we can map it to a bell curve and standardize any specific result. Z-scores normalize how far in units of standard deviation a result is from the mean. This tells us how likely it is to occur or how unusual it is if the data conforms to a Gaussian distribution.
The key point is that in the process of finding the standard deviation, we squared the differences. This will give outliers a higher weight in the computation of variance.
Let’s consider an example
If 49 students score an 85 on a test and 1 scores a zero we see:
mean = 83.3
standard deviation = 11.9
ComputationsMean
(49 x 85) + (1 x 0) = 4165
4165/50 = 83.3
The class mean is 83.3
Standard deviation using the recipe above?
Difference of each score from the mean:
49 students scored 1.7 points from the mean (they scored an 85 vs a mean of 83.3)
1 student scored 83.3 points away from the mean
Square the differences
49 students each had a squared difference of 1.7² = 2.89
1 student had a squared difference of 83.3² = 6938.89
Sum the squared differences
49 x 2.89 = 141.61
1 x 6938.89 (notice how this 1 student’s difference swamped all the other students’ differences combined)
141.61 + 6938.89 = 7080.5
Find the mean of the squared differences
7080.5 / 50 students = 141.61
The variance = 141.61
Compute the standard deviation
sqrt(141.61) = 11.9
The standard deviation of scores on this test is 11.9
You’re jumping up and down — “These scores are not distributed like a bell curve!”
There’s a single outlier and everyone else scored the same.
The standard deviation doesn’t feel like a number that represents a typical result. It feels off here.
Mean Absolute Deviation (MAD)
An alternative to the standard deviation is the mean absolute deviation. The recipe for computing it feels similar to standard deviation but we don’t square differences.
The outliers don’t get exponentially weighted.
To compute the MAD for the test scores:
Sum all the absolute differences from the mean
We count 49 differences of 1.7 from the mean of 83.3
We count one difference of 83.3 (ie abs[0-83.3])
sum of absolute differences = 49 x 1.7 + 83.3 = 166.6
Note that the one outlier represents half of the total differences in this example — but this is a much smaller weight than that outlier had on the total variance when we squared the differences.
Take the average difference from the mean
166.6 / 50 = 3.33
That’s it…the MAD is 3.33
🧮
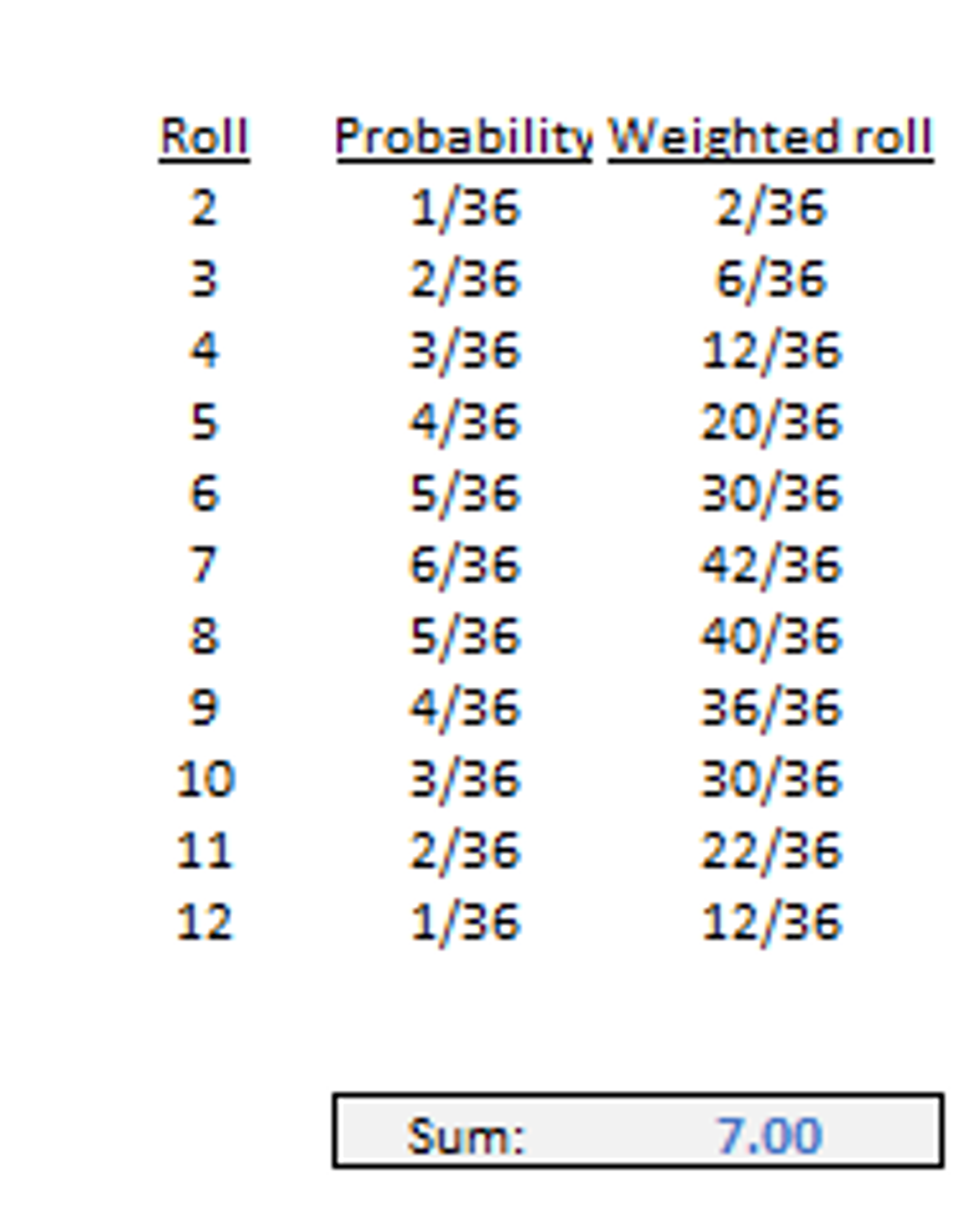
More practice
Compute the mean, standard deviation, and mean absolute deviation (MAD) for rolling 2 dice.
Solution
Relating MAD to SD
With our test example, we computed 2 different measures of spread or variation.
Standard deviation = 11.9
MAD = 3.33
You’ll notice that MAD is smaller than SD. This is always true. Squaring vs not squaring. There are formal proofs of this online as well.
In this example, the MAD is 27% of the SD.
I’d say that the MAD did a better job of telling us what was typical — most students scored closely to the mean.
But is the 27% ratio of MAD to SD mean anything? Is it normal for those stats to differ by that much?
If you worked out the solution to the dice problem above in More Practice, you’ll find that the MAD is 1/3 of the SD.
We also know that the sum of 2 dice looks symmetrical like a pyramid. If there were many more sides on each die the results would probably start moving from a pyramid shape to a more continuous bell curve shape.
It turns out that a Gaussian distribution has a fixed ratio of MAD to SD!
You could expect the ratio to differ for non-Gaussian distributions. When examining data, computing both statistics can give you a clue about its nature.
In the text example above, the MAD/SD ratio of only 27% is a clue:
Even though the MAD is more useful than SD for telling us what outcomes are typical, the ratio indicates that there are some highly skewed outliers.



![[Arkieva calculus derivation]](https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2F0cf10c00-9599-48d1-b309-4bb16acbc805%2F4bbcf404-7688-4683-99cf-0d8b910f27d5%2FUntitled.png?table=block&id=0f3701ce-0a5b-481a-9069-728af5cb2fcd&cache=v2)